
Data Masking for Amazon Athena
Introduction
In April 2024, Mandiant reported a significant threat to Snowflake Data Warehouse users. The attack exploited stolen credentials to access and compromise valuable data. This incident highlights the growing importance of robust cloud security measures in today’s digital landscape. Data masking helps protect sensitive information by reducing the risk of exposure in scenarios like this one. Amazon Athena, a powerful serverless query service, handles vast amounts of data. Let’s explore the basics of data masking for Amazon Athena and how it can safeguard your sensitive data.
Understanding Data Masking in Amazon Athena
Data masking is a technique used to create a structurally similar but inauthentic version of an organization’s data. This process aims to protect sensitive information while maintaining data utility for testing or analysis purposes.
Why is Data Masking Important?
- Compliance: Many regulations require protecting personal and sensitive data.
- Risk Reduction: Masked data minimizes the risk of data breaches.
- Testing and Development: It allows for safe use of production-like data.
Native Masking Techniques in Amazon Athena
Amazon Athena offers several native masking techniques using SQL language features, views, stored procedures, and AWS CLI. Let’s explore these methods.
SQL Language Features
Athena supports various SQL functions that can be used for data masking:
- SUBSTR(): Extracts part of a string.
- CONCAT(): Combines strings.
- REGEXP_REPLACE(): Replaces text using regular expressions.
Views for Data Masking
Views can provide a layer of abstraction, allowing you to mask data without modifying the original table.
Example:
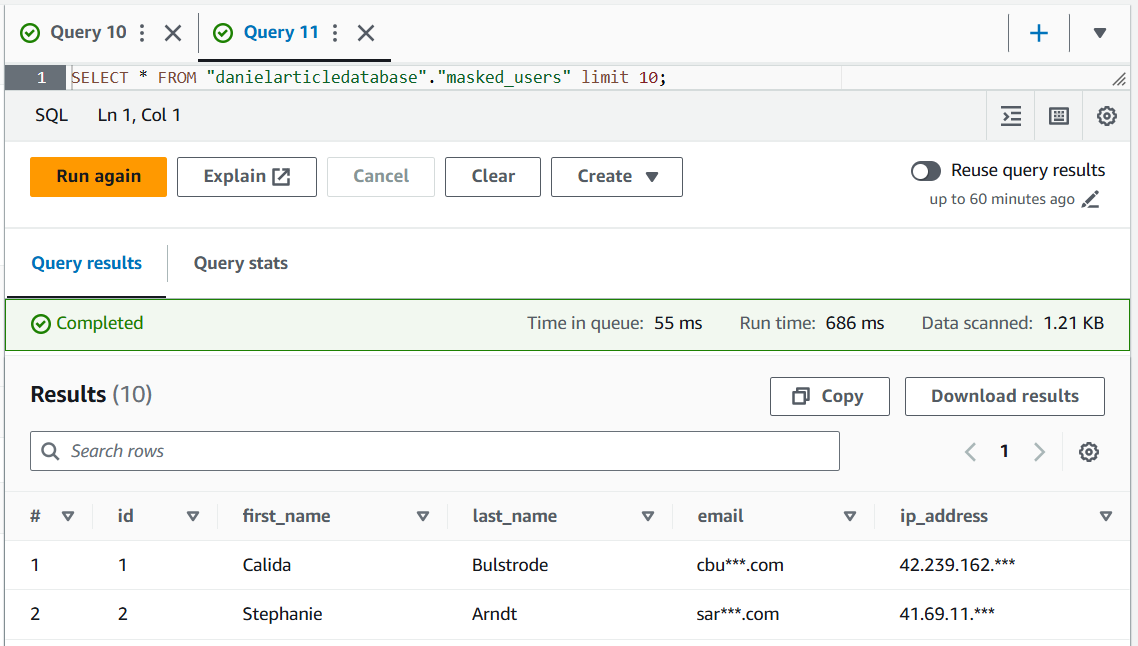
CREATE OR REPLACE VIEW masked_users AS SELECT id, first_name, last_name, -- Mask email CONCAT(SUBSTR(email, 1, 3), '***', SUBSTR(email, -4)) AS email, -- Mask IP address REGEXP_REPLACE(ip_address, '(\d+\.\d+\.\d+\.)\d+', '$1***') AS ip_address FROM danielarticletable;
SELECT * FROM "danielarticledatabase"."masked_users" limit 10;
The output can be as follows:
Stored Procedures and access control
It’s important to understand that Amazon Athena is not a traditional database, but rather a query service. As such, it doesn’t store procedures or manage users in the same way a conventional database would. This is why we’ve explored alternative masking approaches, such as views and built-in SQL functions.
Athena’s user management and access control are handled through AWS Identity and Access Management (IAM), providing a robust, cloud-native security model. However, this means that data masking rules typically need to be implemented at the application level, where access control is enforced.
For organizations seeking a more centralized and uniform approach to access control and data masking, solutions like DataSunrise can be valuable. When used in proxy mode, DataSunrise allows database administrators to implement consistent masking rules and access controls across different data sources, including Athena. This approach can significantly enhance the robustness and manageability of data protection measures, especially in complex, multi-service environments.
AWS CLI for Data Masking
The AWS Command Line Interface (CLI) offers a powerful way to automate data masking in Amazon Athena. For a practical example of this approach, check out our article on dynamic masking, which demonstrates how to efficiently implement and manage data protection using CLI commands.
Python and Boto3 for Native Masking in Athena
Let’s explore how to use Python and Boto3 to connect to Athena, copy data, and mask emails.
import boto3
import time
import pandas as pd
def wait_for_query_to_complete(athena_client, query_execution_id):
max_attempts = 50
sleep_time = 2
for attempt in range(max_attempts):
response = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
state = response['QueryExecution']['Status']['State']
if state == 'SUCCEEDED':
return True
elif state in ['FAILED', 'CANCELLED']:
print(f"Query failed or was cancelled. Final state: {state}")
return False
time.sleep(sleep_time)
print("Query timed out")
return False
# Connect to Athena
athena_client = boto3.client('athena')
# Execute query
query = "SELECT * FROM danielArticleDatabase.danielArticleTable"
response = athena_client.start_query_execution(
QueryString=query,
ResultConfiguration={'OutputLocation': 's3://danielarticlebucket/AthenaArticleTableResults/'}
)
query_execution_id = response['QueryExecutionId']
# Wait for the query to complete
if wait_for_query_to_complete(athena_client, query_execution_id):
# Get results
result_response = athena_client.get_query_results(
QueryExecutionId=query_execution_id
)
# Extract column names
columns = [col['Label'] for col in result_response['ResultSet']['ResultSetMetadata']['ColumnInfo']]
# Extract data
data = []
for row in result_response['ResultSet']['Rows'][1:]: # Skip header row
data.append([field.get('VarCharValue', '') for field in row['Data']])
# Create DataFrame
df = pd.DataFrame(data, columns=columns)
print("\nDataFrame head:")
print(df.head())
# Mask emails (assuming 'email' column exists)
if 'email' in df.columns:
df['email'] = df['email'].apply(lambda x: x[:3] + '***' + x[-4:] if x else x)
# Save masked data
df.to_csv('danielarticletable_masked.csv', index=False)
print("Masked data saved to danielarticletable_masked.csv")
else:
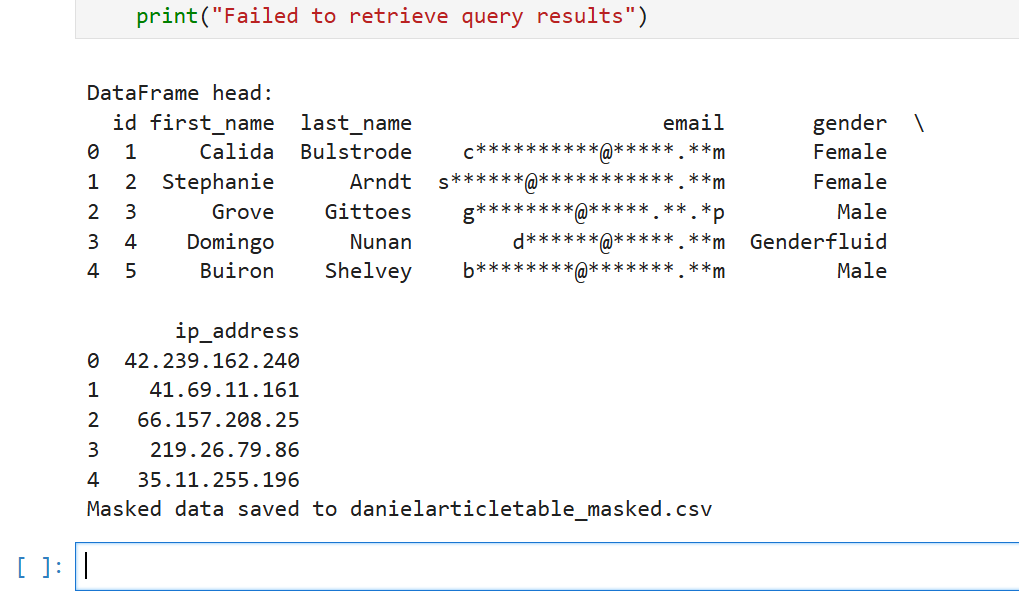
print("Failed to retrieve query results")This script fetches data from Athena, masks the email column, and saves the result in danielarticletable_masked.csv file. The output file is as follows:
id,first_name,last_name,email,gender,ip_address 1,Calida,Bulstrode,cbu***.com,Female,42.239.162.240 2,Stephanie,Arndt,sar***.com,Female,41.69.11.161 …
AWS credentials were set in the Python virtual environment. The masking script output for Jupyter Notebook in our case was:
Masking with DataSunrise
While native masking is useful, DataSunrise masking offers more flexibility. It provides both dynamic and static masking capabilities for Amazon Athena.
Creating a DataSunrise Dynamic Masking Rule
- Navigate to ‘Masking and Dynamic Masking’ in the Main Menu.
- Create a new masking rule.
- Select the ‘Amazon Athena’ instance as the Rule Instance.
- Configure the masking rule by specifying which columns to mask.
- Save the rule. It will activate automatically upon saving.
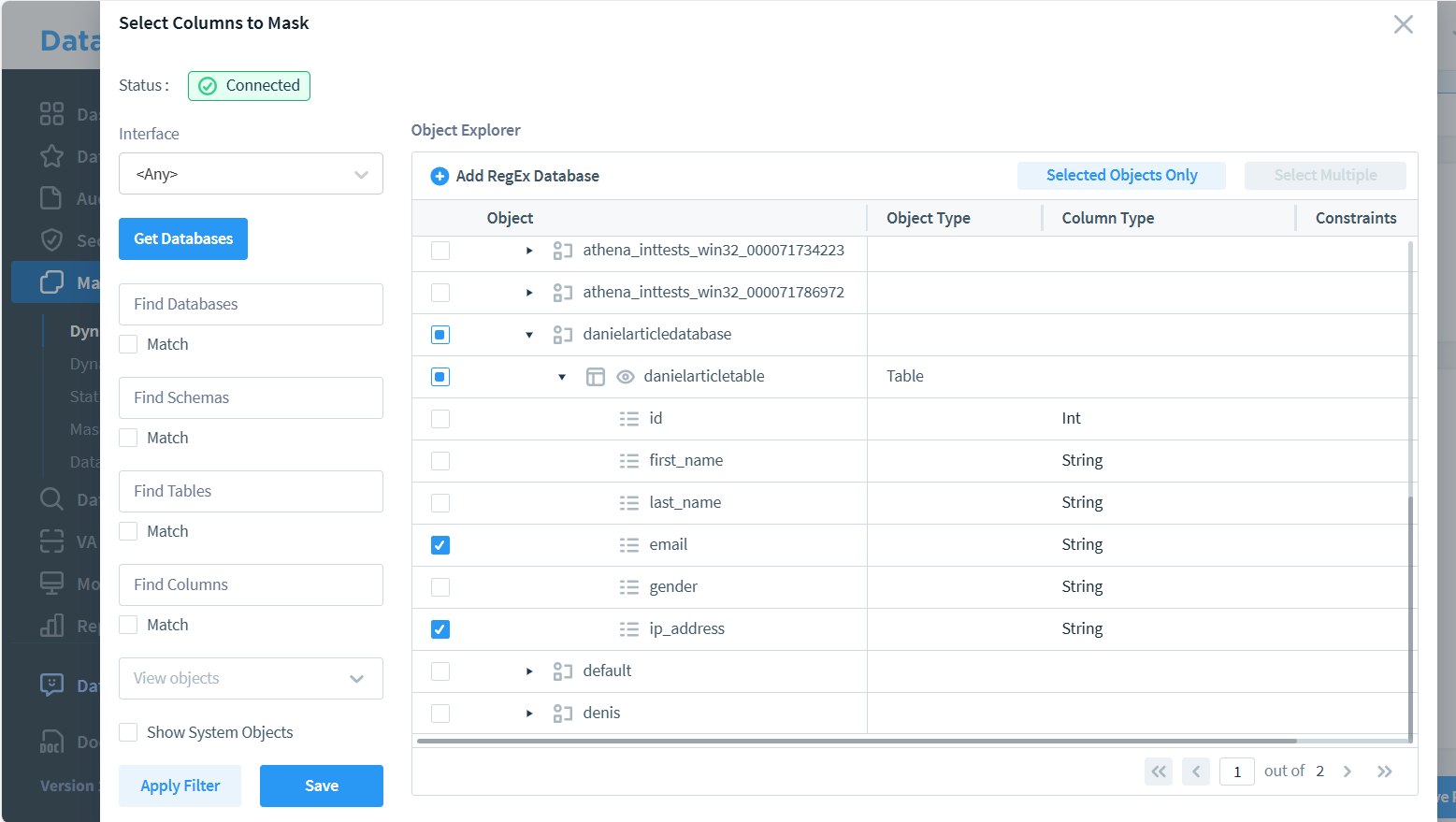
In the image above, you can see two columns marked for masking. However, selecting multiple columns in a single rule may limit your available masking methods. If you need different masking techniques for each field, consider creating separate rules for each column. This approach provides greater flexibility in choosing appropriate masking methods for individual data types.
Benefits of DataSunrise for Centralized Masking
- Unified Control: Manage masking rules across multiple data sources.
- Real-time Protection: Apply masking dynamically as queries are executed.
- Flexible Rules: Create complex masking patterns based on user roles or data sensitivity.
- Audit Trail: Keep track of all data access and masking activities.
Athena Static Data Masking with DataSunrise
Amazon Athena is a query service rather than a traditional database, which means direct static masking in DataSunrise is not supported for Athena. However, there are effective workarounds available. For detailed information on these alternative approaches, please refer to our dedicated article on Athena static data masking strategies.
Best Practices for Data Masking in Amazon Athena
- Identify Sensitive Data: Regularly audit your data to identify sensitive information.
- Use Multiple Techniques: Combine native Athena features with third-party tools like DataSunrise.
- Test Thoroughly: Ensure masking doesn’t break application functionality.
- Update Regularly: Review and update masking rules as data evolves.
- Monitor and Audit: Keep track of who accesses masked data and when.
Conclusion
Data masking for Amazon Athena is a crucial aspect of data security. By leveraging native Athena features and powerful tools like DataSunrise, organizations can protect sensitive information while maintaining data utility. Remember, effective data masking is an ongoing process that requires vigilance and regular updates.
As data breaches become more common, investing in robust data masking techniques is not just a best practice—it’s a necessity for responsible data management.
DataSunrise offers flexible and cutting-edge tools for database security, including comprehensive audit and compliance tools. For a firsthand experience of our powerful data protection suite, we invite you to visit our website and schedule our online demo.
