
Data Masking for Amazon Redshift

Introduction
With the increasing use of cloud data warehouses like Amazon Redshift, organizations face new challenges in safeguarding their valuable data. Internal actors are responsible for nearly half (49%) of data breaches in Europe, the Middle East, and Africa, indicating frequent occurrences of insider threats such as privilege abuse and unintentional employee mistakes. This alarming statistic highlights the importance of implementing robust security measures, such as data masking, to protect sensitive information and ensure regulatory compliance.
Understanding Data Masking for Amazon Redshift
Data masking is a powerful technique used to protect sensitive data in Redshift by replacing it with fictitious but realistic information. When applied to Amazon Redshift, it helps organizations maintain data privacy while allowing authorized users to access and analyze the information they need.
Why is Data Masking Important?
- Protects sensitive data from unauthorized access
- Ensures compliance with regulations like GDPR and HIPAA
- Reduces the risk of data breaches and insider threats
- Enables safe use of production data in non-production environments
Amazon Redshift’s Native Data Masking Capabilities
Amazon Redshift offers built-in data masking functions that can help protect sensitive information. These functions allow you to mask data directly within your queries or views.
Key Redshift Data Masking Functions
We use the following table with the synthetic data by mockaroo.com:
create table MOCK_DATA ( id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50) ); insert into MOCK_DATA (id, first_name, last_name, email) values (1, 'Garvey', 'Dummer', 'gdummer0@booking.com'); insert into MOCK_DATA (id, first_name, last_name, email) values (2, 'Sena', 'Trevna', 'strevna1@youku.com'); …
When utilizing native masking features, you can employ constructions such as:
SELECT RIGHT(email, 4) AS masked_email FROM mock_data;
SELECT 'XXXX@XXXX.com' AS masked_email FROM mock_data;
CREATE VIEW masked_users AS
SELECT
id,
LEFT(email, 1) || '****' || SUBSTRING(email FROM POSITION('@' IN email)) AS masked_email,
LEFT(first_name, 1) || REPEAT('*', LENGTH(first_name) - 1) AS masked_first_name
FROM mock_data;
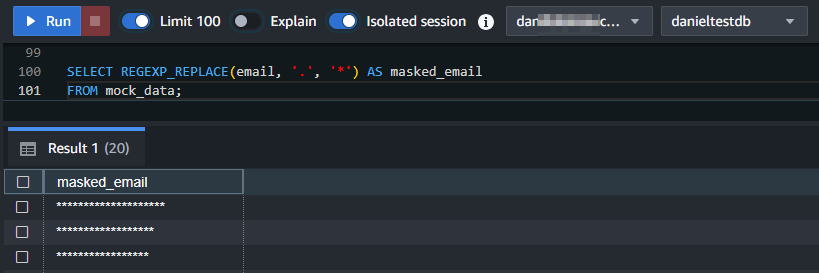
SELECT * FROM masked_users;SELECT REGEXP_REPLACE(email, '.', '*') AS masked_email FROM mock_data;
The result for REGEXP_REPLACE example replace is shown below:
More complex approach may involve the built-in Redshift Python functions.
-- Mask Email --
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
Dynamic vs. Static Data Masking
When implementing data masking for Amazon Redshift, it’s essential to understand the difference between dynamic and static masking.
Dynamic Data Masking
Dynamic masking applies the masking rules in real-time when data is queried. This approach offers flexibility and doesn’t modify the original data.
Benefits of dynamic masking:
- No changes to the source data
- Masking rules can be easily updated
- Different users can see different levels of masked data
Static Data Masking
Static masking permanently alters the data in the database. This method is typically used when creating copies of production data for testing or development purposes.
Advantages of static masking:
- Consistent masking across all environments
- Reduced performance impact on queries
- Suitable for creating sanitized data sets
Creating a DataSunrise Instance for Dynamic Data Masking
To implement advanced dynamic data masking for Amazon Redshift, you can use third-party solutions like DataSunrise. Here’s how to get started with DataSunrise:
- Log in to your DataSunrise dashboard
- Navigate to the “Instances” section
- Click “Add Instance” and select “Amazon Redshift”
- Enter your Redshift connection details
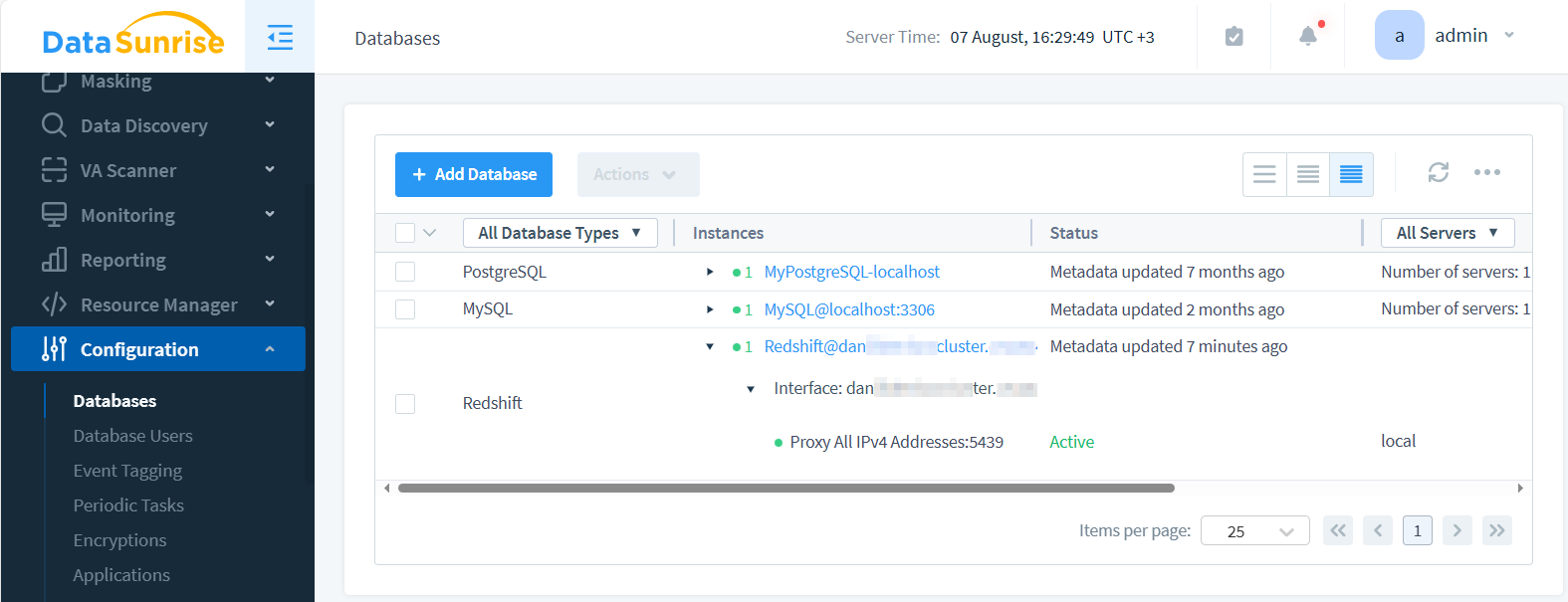
The image below depicts the newly created instance, which appears at the end of the list.
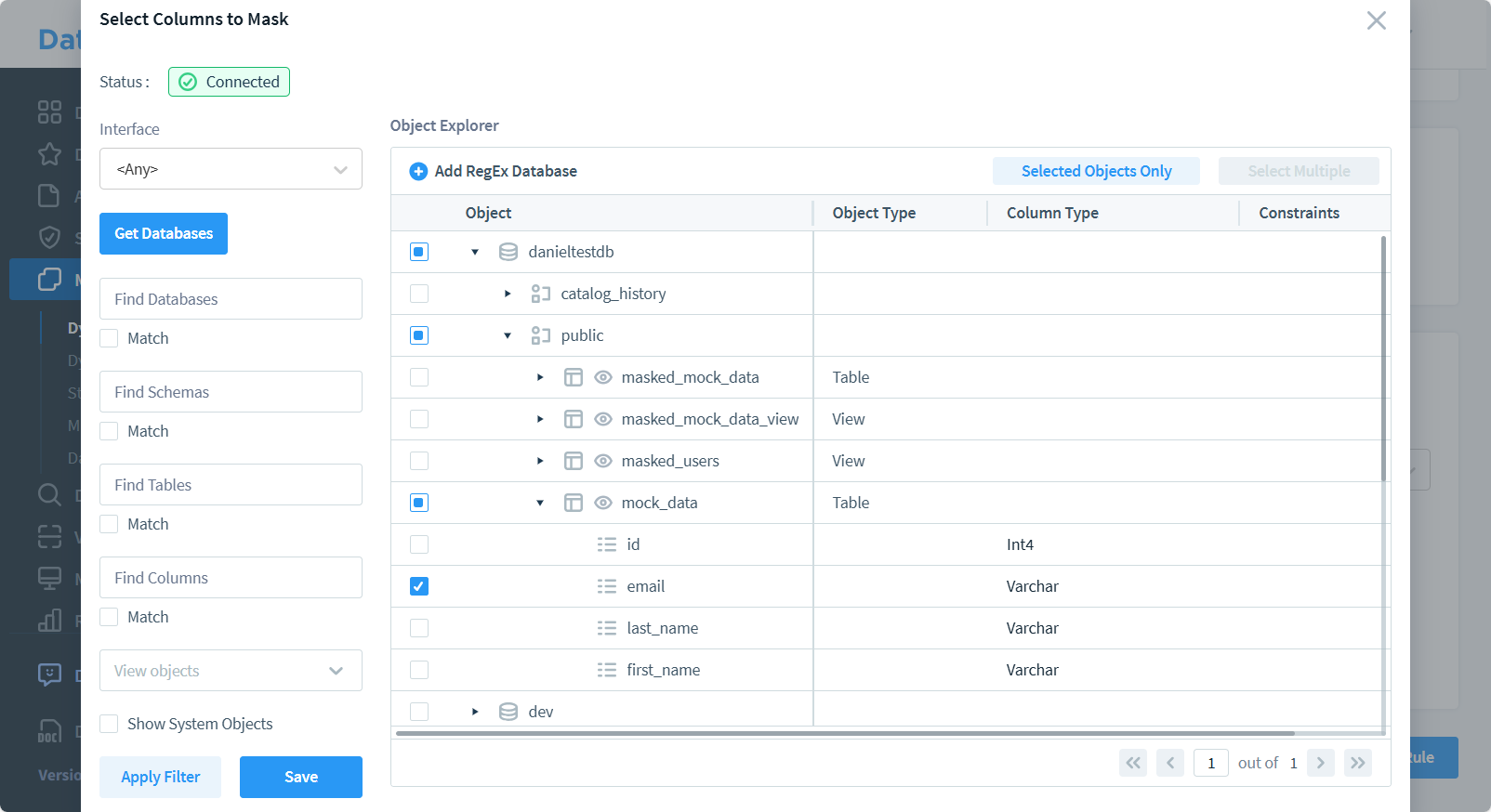
- Configure the masking rules for sensitive columns
- Save and apply the configuration
Once set up, you can view dynamically masked data by querying your Redshift instance through DataSunrise’s proxy.
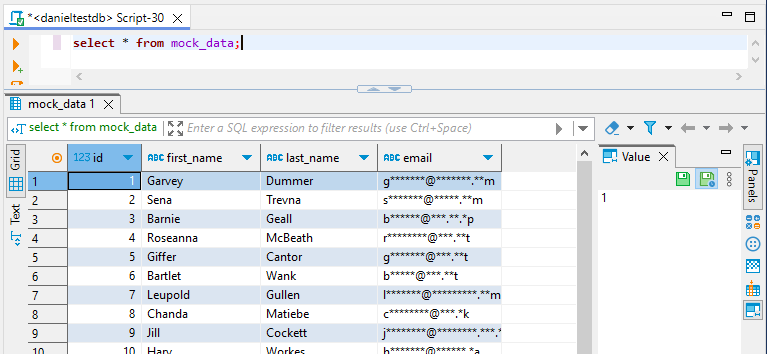
Notice that the email column is masked. This demonstrates a dynamic masking rule in action. The data is obfuscated in real-time as the query executes, protecting sensitive information without altering the underlying data.
Best Practices for Data Masking in Amazon Redshift
To ensure effective data protection, follow these best practices:
- Identify and classify sensitive data
- Use a combination of masking techniques
- Regularly review and update masking rules
- Monitor access to masked data
- Train employees on data privacy policies
Ensuring Regulatory Compliance with Data Masking
Data masking plays a crucial role in meeting regulatory requirements. By implementing robust masking strategies, organizations can:
- Protect personally identifiable information (PII)
- Ensure data minimization principles
- Maintain data integrity while preserving privacy
- Demonstrate due diligence in data protection efforts
Challenges and Considerations
While data masking offers significant benefits, it’s important to be aware of potential challenges:
- Performance impact on queries
- Maintaining data consistency across systems
- Balancing security with data usability
- Handling complex data relationships
Future Trends in Data Masking for Cloud Data Warehouses
As cloud adoption continues to grow, we can expect to see advancements in data masking technologies:
- AI-powered masking algorithms
- Integration with data governance platforms
- Enhanced cross-cloud compatibility
- Automated compliance reporting
DataSunrise has already implemented all the feature trends listed here, making our product the leading solution for multi-storage environments.
Conclusion
Data masking for Amazon Redshift is a critical component of a comprehensive data protection strategy. By implementing effective masking techniques, organizations can safeguard sensitive information, ensure regulatory compliance, and mitigate the risks associated with data breaches. As the threat landscape evolves, it’s crucial to stay informed about the latest data masking technologies and best practices.
For those seeking advanced data protection solutions, DataSunrise offers user-friendly and cutting-edge tools for database security, including audit and data discovery features. To experience the power of DataSunrise’s comprehensive data protection suite, visit our website for an online demo and take the first step towards securing your valuable data assets.
