
Mastering Data Requirements in System Testing: Best Practices

Introduction
In the world of software development, system testing plays a crucial role in ensuring the quality and reliability of applications. At the heart of effective system testing lies the proper management of data requirements. This article delves into the essentials of data requirements in system testing, exploring various testing methods and their specific data needs.
Understanding System Testing and Test Data
System testing is a critical phase in the software development lifecycle. It involves evaluating the complete, integrated software system to ensure it meets specified requirements. But what fuels this process? The answer is test data.
The Importance of Test Data
Test data serves as the foundation for thorough system testing. It allows testers to:
- Simulate real-world scenarios
- Uncover potential bugs and issues
- Validate system performance under various conditions
Types of Test Data
Effective system testing requires diverse types of test data:
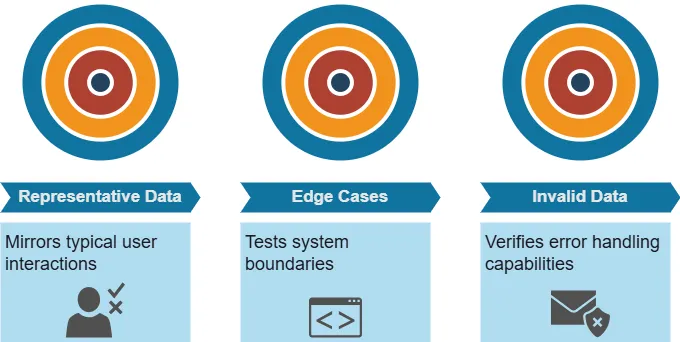
Synthetic Data in System Testing
When real data is scarce or sensitive, synthetic data comes to the rescue.
What is Synthetic Data?
Synthetic data is artificially generated information that mimics the characteristics of real data. It’s created using algorithms, statistical models, or specialized data synthesis tools.
DataSunrise offers powerful synthetic data generation capabilities tailored for complex database environments. Our advanced tools can analyze and replicate intricate data relationships, producing highly realistic synthetic datasets that mirror your existing database structure. By leveraging DataSunrise’s technology, organizations can generate comprehensive test data that maintains referential integrity and reflects real-world scenarios, all while safeguarding sensitive information.
Benefits of Synthetic Data
- Customizable to specific testing needs
- No privacy concerns
- Ability to generate large volumes quickly
Example: Generating Synthetic Customer Data
Let’s say you’re testing an e-commerce platform. You could use a data generation tool to create synthetic customer profiles:
import faker
fake = faker.Faker()
for _ in range(1000):
customer = {
"name": fake.name(),
"email": fake.email(),
"address": fake.address(),
"purchase_history": [fake.random_int(10, 1000) for _ in range(5)]
}
# Use this synthetic customer data for testing
This script generates 1000 realistic customer profiles without exposing real customer information.
Masked Data: Balancing Realism and Privacy
Masked data offers a middle ground between real and synthetic data.
What is Data Masking?
Data masking involves modifying sensitive information in a dataset while maintaining its overall structure and characteristics.
DataSunrise offers robust data masking capabilities designed to protect sensitive information while maintaining data integrity. For a comprehensive overview of these features, we recommend reading our dedicated article on data masking techniques (static and dynamic) and best practices.
Common Data Masking Techniques
- Data scrambling: Randomly rearranging values within a column
- Data substitution: Replacing sensitive values with fictional alternatives
- Data encryption: Encoding sensitive information
Example: Masking Customer Data
DataSunrise offers a comprehensive suite of data masking mechanisms, addressing the complex challenges of implementing effective data protection. Our solution includes a wide array of pre-built masking techniques and the flexibility to create custom methods, ensuring that organizations can meet their specific data privacy requirements. With DataSunrise, you have access to both industry-standard and innovative masking approaches, all within a single, powerful platform.
Consider this SQL query for masking customer emails:
UPDATE customers SET email = CONCAT(LEFT(email, 3), '***', RIGHT(email, INSTR(email, '@') - 1));
This query replaces the middle part of email addresses with asterisks, preserving privacy while maintaining the data’s structure.
Volume Testing: Pushing System Limits
Volume testing assesses how a system performs under high data loads.
Purpose of Volume Testing
- Verifies system stability under stress
- Evaluates response times with large datasets
- Assesses resource utilization during peak loads
Data Requirements for Volume Testing
- Large datasets (often millions of records)
- Varied data types to simulate real-world scenarios
- Data generation tools for efficient test data creation
Example: Volume Testing a Database
Imagine you’re volume testing a customer database. You might use a script to generate and insert millions of records:
import psycopg2
import faker
fake = faker.Faker()
conn = psycopg2.connect("dbname=testdb user=postgres password=secret")
cur = conn.cursor()
for _ in range(1000000): # Generate 1 million records
cur.execute("INSERT INTO customers (name, email, address) VALUES (%s, %s, %s)", (fake.name(), fake.email(), fake.address()))
conn.commit()
cur.close()
conn.close()This script populates the database with a large volume of data, allowing you to test system performance under realistic conditions.
Data-Driven Testing Across Different Testing Forms
It’s important to note that data-driven tests can be applied in various forms of testing, including unit testing, integration testing, and acceptance testing. Each type of testing may require different data sets and approaches, but the core principle remains the same: using carefully prepared test data to validate system behavior under different scenarios.
The specific requirements for test data in each testing phase should be outlined in the Software Test Specification. This document serves as a bridge between requirements and testing activities, detailing the approach, resources, and schedule for testing activities, including the necessary data requirements for each testing phase.
Conclusion: The Vital Role of Data in System Testing
Effective system testing hinges on properly managing data requirements. From synthetic and masked data to volume testing and data-driven testing strategies, each aspect plays a crucial role in ensuring software quality and reliability.
By understanding and implementing these data-driven testing strategies, development teams can:
- Uncover potential issues before they reach production
- Ensure systems perform well under various conditions
- Maintain data privacy and security throughout the testing process
As software systems grow more complex, the importance of robust testing methodologies and data management practices will only increase. By staying informed about these techniques, developers and testers can contribute to creating more reliable, efficient, and secure software solutions.
For those seeking user-friendly and flexible tools for database security, including highly useful synthetic data and data masking capabilities, consider exploring DataSunrise’s offerings. Our comprehensive suite of database security tools can significantly enhance your testing and development processes. Visit the DataSunrise website for an online demo and discover how our solutions can streamline your data management and security efforts.
