
Improving Data Management and Performance with Data Subsetting
Introduction
The explosion of digital technologies, Internet of Things (IoT) devices, and online interactions has created vast amounts of data that can be collected and analyzed. In today’s data-driven world, managing large datasets efficiently is crucial for businesses and researchers alike. One powerful technique that has gained prominence in recent years is data subsetting. This article will dive deep into the world of data subsetting, exploring its fundamentals, benefits, and practical applications. We’ll also look at some open-source tools and provide examples to help you get started with this essential data management technique.
What is Data Subsetting?
Data subsetting is the process of creating a smaller, more manageable portion of a larger dataset while maintaining its key characteristics and relationships. This technique allows users to work with a representative sample of data, making it easier to handle, analyze, and test without compromising the integrity of the original dataset.
Why Should You Be Interested in Subsetting?
Data subsetting is becoming increasingly crucial in our big data era. Here’s why you should pay attention to this technique:
- Handling Massive Datasets: Modern datasets can be enormous. For instance, a social media platform might generate petabytes of data daily. Working with such vast amounts of data can be impractical or impossible without subsetting.
- Resource Optimization: Processing full datasets often requires significant computational resources. Subsetting allows you to work with a fraction of the data, saving time and reducing hardware requirements.
- Cost Reduction: Cloud computing and storage costs are directly tied to data volume. By working with subsets, you can significantly reduce these expenses.
- Faster Development Cycles (software testing): In software development, using full production datasets for testing can slow down the development process. Subsets allow for quicker iterations and faster bug identification.
- Data Privacy Compliance: With regulations like GDPR and CCPA, using full datasets with sensitive information for testing or analysis can be risky. Subsetting helps create anonymized, compliant datasets.
- Improved Data Quality: Smaller datasets are easier to clean and validate, potentially leading to higher quality data for your analyses or models.
How Large Can Datasets Be? A Real-World Example
To understand the scale of modern datasets, let’s consider a few examples:
- Walmart’s Data Warehouse: As of 2019, Walmart’s data warehouse was estimated to hold over 2.5 petabytes of data. That’s equivalent to 167 times all the books in the US Library of Congress.
- Facebook’s User Data: Facebook processes over 500 terabytes of data every day. This includes user posts, photos, videos, and interaction data.
- CERN’s Large Hadron Collider: The LHC generates huge amounts of data equivalent to over 20 000 years of 24/7 HD video recording.
- Genomics Data: The human genome consists of about 3 billion base pairs. Sequencing and storing this data for millions of individuals creates datasets in the petabyte range.
- Climate Science: NASA’s Center for Climate Simulation (NCCS) manages over 32 petabytes of data from various Earth science missions.
To put this in perspective, 1 petabyte is equivalent to 20 million four-drawer filing cabinets filled with text. Now imagine trying to analyze or process this amount of data in its entirety – that’s where data subsetting becomes invaluable.
For instance, if you were a data scientist at Walmart trying to analyze customer behavior, working with the full 2.5 petabytes would be impractical. Instead, you might create a subset of data for a specific time period, region, or product category, perhaps reducing your working dataset to a more manageable 50 gigabytes.
Practical Applications of Subsetting
Let’s explore some real-world scenarios where data subsetting proves invaluable:
1. Software Development and Testing
Developers often need to work with realistic data for testing applications. However, using full production datasets can be impractical and risky. Subsetting allows the creation of smaller, representative test datasets that maintain the complexity of real-world data without exposing sensitive information.
2. Data Analysis and Exploration
When dealing with massive datasets, initial exploratory data analysis can be time-consuming. By creating a subset, analysts can quickly gain insights and test hypotheses before scaling up to the full dataset.
3. Machine Learning Model Development
During the early stages of model development, data scientists can use subsets to iterate quickly on different algorithms and hyperparameters before training on the full dataset.
4. Database Optimization
Database administrators can use subsetting to create smaller versions of production databases for development and testing environments, ensuring optimal performance without the overhead of managing full-size replicas.
Data Compliance Overview | Regulatory Frameworks
Automated, Policy-Driven Subsetting & Masking
Hand-built SQL extracts break the moment schemas change. Modern teams instead rely on automated discovery, rule engines, and dynamic masking to generate compliant subsets on demand. DataSunrise scans source systems, fingerprints sensitive columns, and then builds referentially-intact slices—complete with on-the-fly masking for PII or PHI—so QA and analytics teams never touch raw production data.
Each export is versioned, logged, and reproducible via REST API, giving auditors a clear trail while letting DevOps trigger fresh, downsized copies in CI/CD pipelines. The result: faster dev cycles, lower cloud costs, and airtight compliance without rewriting a single query.
Tools and Techniques for Data Subsetting
Now that we understand the importance of data subsetting, let’s look at some popular tools and techniques to implement it effectively.
SQL for Data Subsetting
SQL is a powerful language for data manipulation and is excellent for subsetting relational databases. Here’s an example of how to create a subset of data using SQL:
-- Create a subset of customer data for the year 2023 CREATE TABLE customer_subset_2023 AS SELECT * FROM customers WHERE EXTRACT(YEAR FROM order_date) = 2023 LIMIT 10000;
This query creates a new table customer_subset_2023 containing up to 10,000 customer records from the year 2023. The result is a smaller, more manageable dataset for analysis or testing purposes.
Python for Data Subsetting
With its rich ecosystem of data manipulation libraries, Python offers powerful tools for data subsetting.
It features a built-in data type called ‘set’, which is useful for storing unique elements and performing mathematical set operations. However, while sets are efficient for certain tasks, they are not typically used for big data operations. For handling large datasets in Python, specialized libraries like pandas, NumPy, or PySpark are more commonly employed due to their optimized performance and advanced data manipulation capabilities.
Let’s look at an example using pandas:
import pandas as pd
import numpy as np
# Load the full dataset
full_dataset = pd.read_csv('large_dataset.csv')
# Create a subset based on a condition and random sampling
subset = full_dataset[full_dataset['category'] == 'electronics'].sample(n=1000, random_state=42)
# Save the subset to a new CSV file
subset.to_csv('electronics_subset.csv', index=False)
This script loads a large dataset, filters it to include only electronics items, then randomly samples 1,000 rows to create a subset. The result is saved as a new CSV file.
Also, in Pandas you can data filtering with statements like following:
filtered_df_loc = df.loc[df['age'] > 25, ['name', 'city']]
or
filtered_df = df[df['age'] > 25]
Condition-based Data Filtering in R
R is another powerful language for data manipulation and analysis, widely used in statistical computing and data science. While Python is often preferred for deep learning, R has strong capabilities in statistical learning and traditional machine learning. This can be advantageous when your data subsetting involves model-based approaches or when you need to analyze the statistical properties of your subsets.
You can run this code in Posit Cloud version of RStudio free account.
# Load necessary library
library(dplyr)
# Let's assume we have a large dataset called 'full_dataset'
# For this example, we'll create a sample dataset
set.seed(123) # for reproducibility
full_dataset <- data.frame(
id = 1:1000,
category = sample(c("A", "B", "C"), 1000, replace = TRUE),
value = rnorm(1000)
)
# Create a subset based on a condition and random sampling
subset_data <- full_dataset %>%
filter(category == "A") %>%
sample_n(100)
# View the first few rows of the subset
head(subset_data)
# Save the subset to a CSV file
write.csv(subset_data, "category_A_subset.csv", row.names = FALSE)
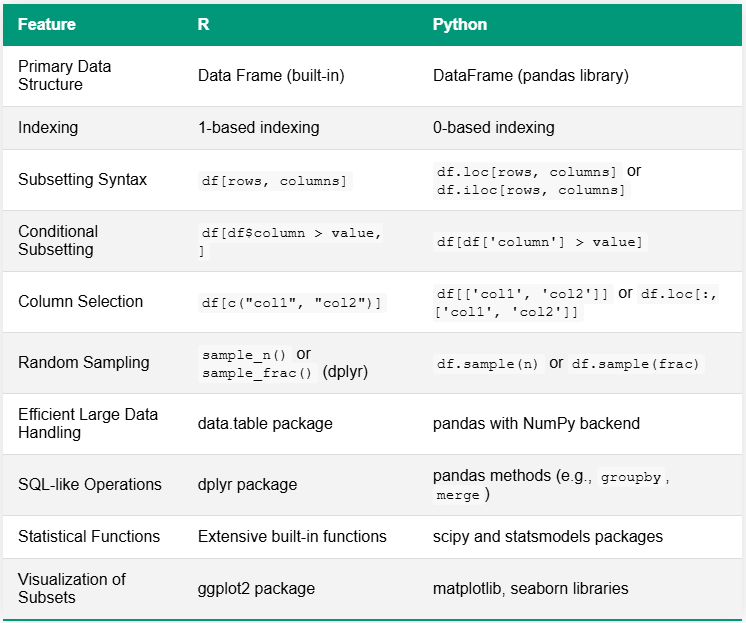
The table below compares R and Python for data subsetting tasks, highlighting key differences in syntax and functionality. A notable distinction lies in their ecosystems: R often has built-in functions or relies on a few comprehensive packages, while Python typically utilizes a variety of specialized libraries for similar capabilities.
Open-Source Tools for Data Subsetting
Several open-source tools are available for more advanced needs:
- Jailer: A database subsetting tool that preserves referential integrity.
- Benerator CE: An open-source framework for generating and subsetting test data.
- Subsetter: A Python library for subsetting relational databases while maintaining referential integrity.
These tools offer more sophisticated features like maintaining complex relationships between tables and generating synthetic data to complement subsets.
Best Practices for Effective Data Subsetting
To make the most of data subsetting, consider these best practices:
- Maintain Data Integrity: Ensure that your subset preserves the relationships and constraints of the original dataset.
- Use Representative Samples: Strive to create subsets that accurately represent the characteristics of the full dataset.
- Consider Data Sensitivity: When subsetting for testing or development, be mindful of sensitive information and apply appropriate anonymization techniques.
- Document Your Process: Keep clear records of how subsets were created to ensure reproducibility.
- Validate Your Subsets: Regularly check that your subsets still accurately represent the full dataset as it evolves over time.
Conclusion
Data subsetting is a powerful technique that can significantly enhance your data management practices. By creating smaller, more manageable datasets, you can improve performance, reduce costs, and streamline your development and testing processes. Whether you’re using SQL, Python, or specialized tools, mastering data subsetting is an essential skill for any data professional.
As you embark on your data subsetting journey, remember that the key to success lies in maintaining data integrity, ensuring representativeness, and choosing the right tools for your specific needs.
