
How to Implement Dynamic Data Masking in Amazon Aurora
Introduction
As businesses increasingly rely on cloud databases like Amazon Aurora, the need for robust security measures grows. One powerful tool in the data protection arsenal is dynamic data masking. Did you know that 68% of data breaches involve non-malicious human action? This alarming statistic highlights the importance of implementing strong data protection strategies, including dynamic data masking for Amazon Aurora.
What is Dynamic Data Masking?
Dynamic data masking is a security feature that hides sensitive data in real-time as it’s being accessed. Instead of altering the original data, it applies masks or transformations on-the-fly when users query the database. This approach ensures that only authorized users see the full, unmasked data, while others receive masked versions.
Key benefits of dynamic data masking include:
- Enhanced data privacy
- Reduced risk of data breaches
- Simplified compliance with data protection regulations
- Flexibility in managing data access
Amazon Aurora’s Dynamic Data Masking Capabilities
Amazon Aurora, a powerful relational database engine, offers built-in dynamic data masking features. These capabilities allow you to protect sensitive data without modifying your application code.
Setting Up Dynamic Data Masking in Aurora
To implement dynamic data masking in Amazon Aurora PostgreSQL, we can leverage the database’s built-in Row-Level Security (RLS) feature. This approach offers a powerful and flexible way to control data access at a granular level. Let’s walk through the process, starting with creating some sample data and then implementing RLS policies to achieve dynamic masking effects.
-- Create the employees table
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
department VARCHAR(50),
salary NUMERIC(10, 2)
);
-- Insert sample data
INSERT INTO employees (first_name, last_name, email, department, salary) VALUES
('John', 'Doe', 'john.doe@company.com', 'IT', 75000),
('Jane', 'Smith', 'jane.smith@company.com', 'HR', 65000),
('Bob', 'Johnson', 'bob.johnson@company.com', 'IT', 70000),
('Alice', 'Williams', 'alice.williams@company.com', 'Finance', 80000),
('Charlie', 'Brown', 'charlie.brown@company.com', 'HR', 60000);Next, let’s set up the necessary users and roles to demonstrate how different access levels affect data visibility.
-- Create roles CREATE ROLE it_manager; CREATE ROLE hr_manager; CREATE ROLE finance_manager; CREATE ROLE employee; -- Create users and assign roles CREATE USER john_it WITH PASSWORD 'password123'; GRANT it_manager TO john_it; CREATE USER jane_hr WITH PASSWORD 'password123'; GRANT hr_manager TO jane_hr; CREATE USER alice_finance WITH PASSWORD 'password123'; GRANT finance_manager TO alice_finance; CREATE USER bob_employee WITH PASSWORD 'password123'; GRANT employee TO bob_employee; -- Grant necessary privileges GRANT SELECT, INSERT, UPDATE, DELETE ON employees TO it_manager, hr_manager, finance_manager; GRANT SELECT ON employees TO employee; GRANT USAGE, SELECT ON SEQUENCE employees_employee_id_seq TO it_manager, hr_manager, finance_manager;
Let’s now implement Row-Level Security (RLS) to achieve our dynamic data masking goals.
-- Enable RLS on the employees table ALTER TABLE employees ENABLE ROW LEVEL SECURITY; -- Create RLS policies CREATE POLICY employee_self_view ON employees FOR SELECT TO employee USING (email = current_user); CREATE POLICY manager_department_view ON employees FOR ALL TO it_manager, hr_manager, finance_manager USING ( CASE WHEN current_user = 'john_it' THEN department = 'IT' WHEN current_user = 'jane_hr' THEN department = 'HR' WHEN current_user = 'alice_finance' THEN department = 'Finance' END ); -- Create a view for masked salary information CREATE OR REPLACE VIEW masked_employees AS SELECT employee_id, first_name, last_name, email, department, CASE WHEN pg_has_role(current_user, 'hr_manager', 'member') OR pg_has_role(current_user, 'finance_manager', 'member') THEN salary::text ELSE 'CONFIDENTIAL' END AS salary FROM employees; -- Grant access to the view GRANT SELECT ON masked_employees TO it_manager, hr_manager, finance_manager, employee; SELECT * FROM employees;
The last command is the select. All the SQL statements above are executed from postgres user. And since this is an admin he can see all the data in the employees table:
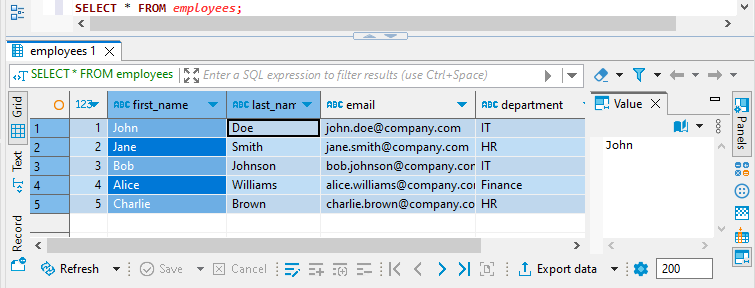
The HR and IT department users can only see their department employees:
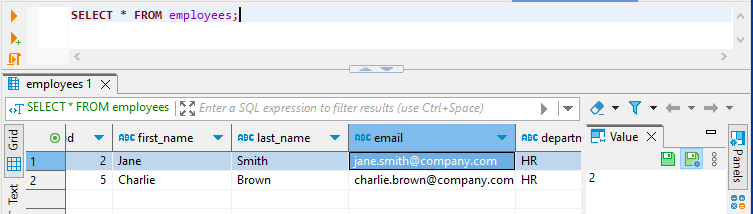
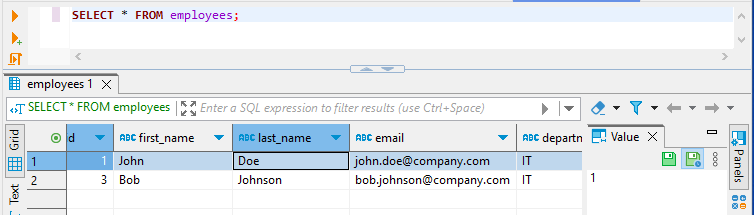
And finally the salary is masked for john_it user in masked_employees view:
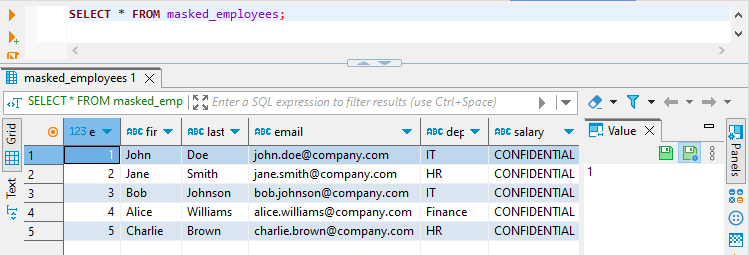
Implementing Dynamic Data Masking with DataSunrise
While Aurora’s native masking capabilities are useful, third-party tools like DataSunrise offer more advanced features and granular control over data masking.
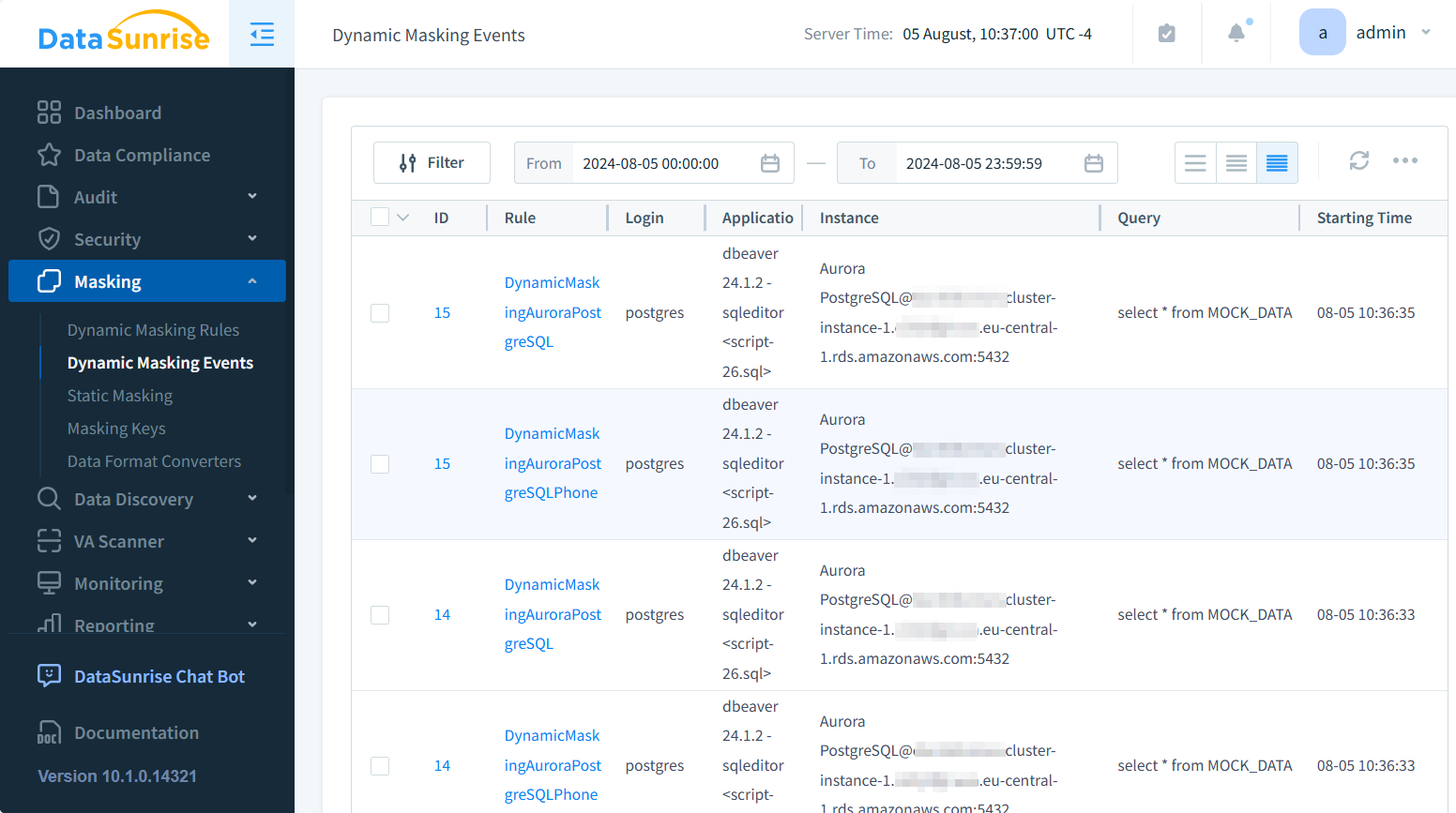
Tracking Masking Events
To monitor the effectiveness of your masking rules, it’s crucial to track masking events. DataSunrise allows you to enable logging for masking events during rule setup
You can then view these logs in the DataSunrise dashboard or export them for further analysis.
Best Practices for Dynamic Data Masking
To get the most out of dynamic data masking for Amazon Aurora, consider these best practices:
- Identify sensitive data: Regularly audit your database to identify and classify sensitive information.
- Use appropriate masking methods: Choose masking techniques that balance security and usability.
- Test thoroughly: Ensure that masking rules don’t break application functionality.
- Monitor and adjust: Regularly review masking logs and adjust rules as needed.
- Combine with other security measures: Use data masking alongside encryption, access controls, and auditing.
Data-Driven Application Testing: Masked vs. Synthetic Data
When testing data-driven applications, two main approaches are available:
- Testing with masked data
- Testing with synthetic data
Masked Data Testing
This approach uses your actual production data but applies masking rules to protect sensitive information. Benefits include:
- Realistic data scenarios
- Easier to set up
- Maintains data relationships
However, there’s still a small risk of data exposure, and masked data may not cover all possible test cases.
Synthetic Data Testing
This method uses artificially generated data that mimics the structure and characteristics of your production data. Advantages include:
- Zero risk of exposing real data
- Can generate edge cases for thorough testing
- Avoids data privacy compliance issues
The downside is that creating realistic synthetic data can be challenging and time-consuming.
Conclusion
Dynamic data masking for Amazon Aurora is a powerful tool for protecting sensitive data in cloud environments. By implementing masking strategies, businesses can significantly reduce the risk of data breaches and simplify compliance with data protection regulations. Whether using Aurora’s native capabilities or advanced tools like DataSunrise, dynamic data masking should be a key component of your database security strategy.
Remember, effective data protection is an ongoing process. Regularly review and update your masking rules, monitor masking events, and stay informed about the latest security best practices to keep your sensitive data safe in the ever-evolving digital landscape.
DataSunrise offers user-friendly and cutting-edge tools for database security, including comprehensive audit capabilities and data discovery features. To learn more about how DataSunrise can enhance your database security and see our solutions in action, visit our website to schedule an online demo.
