
Enhancing Security with Static Data Masking for Amazon Redshift

Introduction
The digital era is in full swing, with 67% of the global population now using the internet. This widespread adoption has catalyzed a significant shift, moving countless processes and services online and transforming how we live, work, and interact. Organizations must balance data utility with regulatory compliance and privacy concerns. One effective solution is static data masking for Amazon Redshift. This technique helps safeguard confidential data while maintaining its usefulness for development and testing.
Let’s explore how static data masking can help secure your Amazon Redshift environment.
Understanding Static Data Masking
What is Static Data Masking?
Static data masking is a process that creates a separate, masked copy of sensitive data. This approach ensures that the original data remains unaltered while providing a safe version for non-production environments.
Why Use Static Data Masking?
- Regulatory compliance
- Reduced risk of data breaches
- Safer development and testing environments
- Maintained data integrity
Amazon Redshift Capabilities for Static Data Masking
Amazon Redshift offers built-in functions and user-defined functions (UDFs) to implement data masking. Let’s examine some key capabilities.
The examples provided above demonstrate data masking techniques but don’t create separate tables with masked data. These methods are similar to those used in native dynamic data masking. For creating permanent obfuscated tables, refer to the ‘Implementing Static Data Masking’ section below.
Built-in Functions
Redshift provides several built-in functions for basic masking operations. One commonly used function is REGEXP_REPLACE.
Example:
SELECT REGEXP_REPLACE(email, '(.*)@', '****@') AS masked_email FROM users;
This query masks the local part of email addresses, replacing it with asterisks.
User-Defined Functions (UDFs)
For more complex masking requirements, Redshift allows creating UDFs using Python. Here’s an example of a UDF that masks email addresses:
CREATE OR REPLACE FUNCTION f_mask_email(email VARCHAR(255))
RETURNS VARCHAR(255)
STABLE
AS $$
import re
def mask_part(part):
return re.sub(r'[a-zA-Z0-9]', '*', part)
if '@' not in email:
return email
local, domain = email.split('@', 1)
masked_local = mask_part(local)
domain_parts = domain.split('.')
masked_domain_parts = [mask_part(part) for part in domain_parts[:-1]] + [domain_parts[-1]]
masked_domain = '.'.join(masked_domain_parts)
return "{0}@{1}".format(masked_local, masked_domain)
$$ LANGUAGE plpythonu;To use this function:
SELECT email, f_mask_email(email) AS masked_email FROM MOCK_DATA;
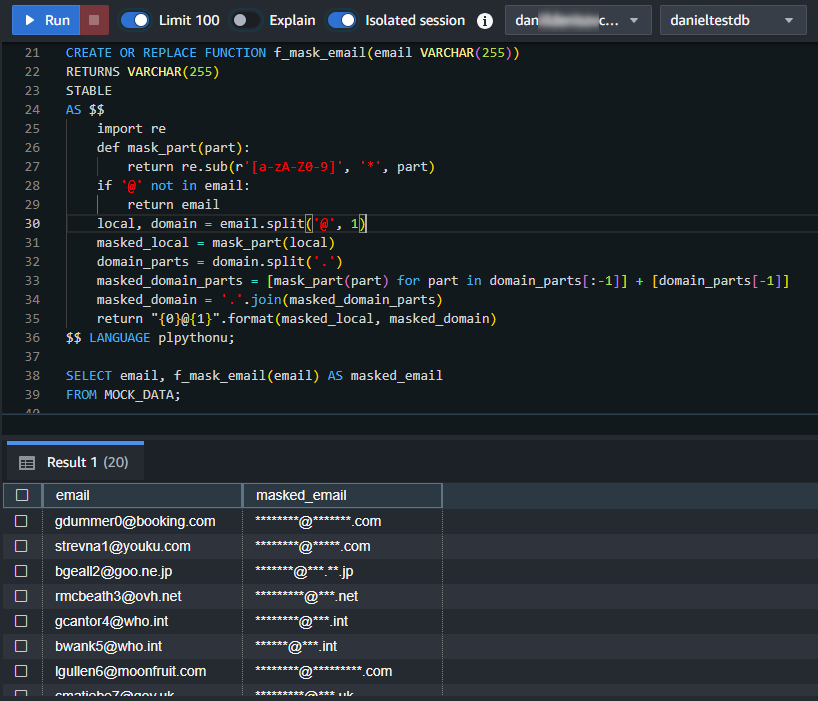
Python functions greatly enhance Redshift’s masking and data processing capabilities. They allow for implementing format-preserved encryption and complex masking procedures. With Python, you can create custom masking algorithms tailored to your specific needs.
Implementing Static Data Masking in Redshift
Now that we understand the basics, let’s look at how to implement static data masking in Redshift.
Step 1: Identify Sensitive Data
First, identify which columns contain sensitive information requiring masking. This may include:
- Personal Identifiable Information (PII)
- Financial data
- Health records
Step 2: Create Masking Functions
Develop masking functions for each data type you need to protect. We’ve already seen an example for email addresses.
Step 3: Create Masked Table
Create a new table with masked data:
CREATE TABLE masked_mock_data AS SELECT id, f_mask_email(email) AS email, first_name, last_name FROM Mock_data;
Step 4: Verify Masked Data
Check the results to ensure proper masking:
SELECT * FROM masked_mock_data;
Static Data Masking with DataSunrise
To use DataSunrise for static masking:
- Configure connection to your Redshift cluster
- Create masking Task in the Web-UI
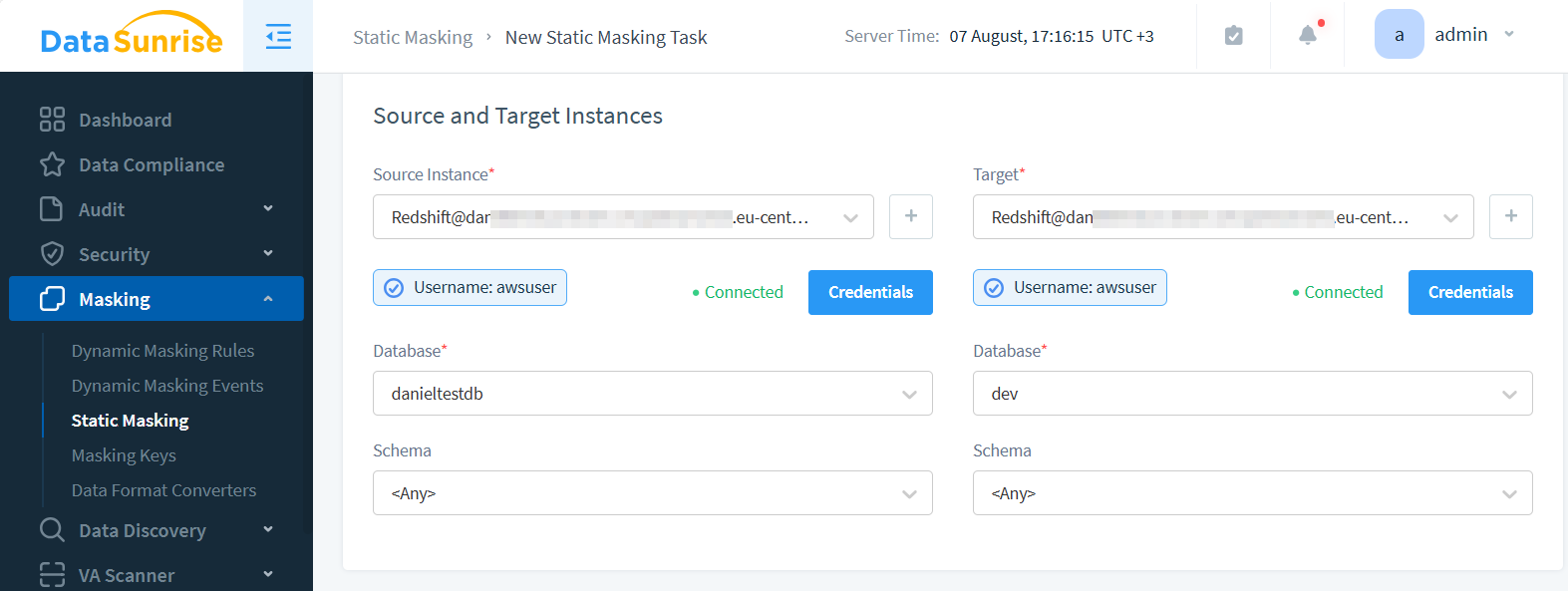
- Select source and target databases.
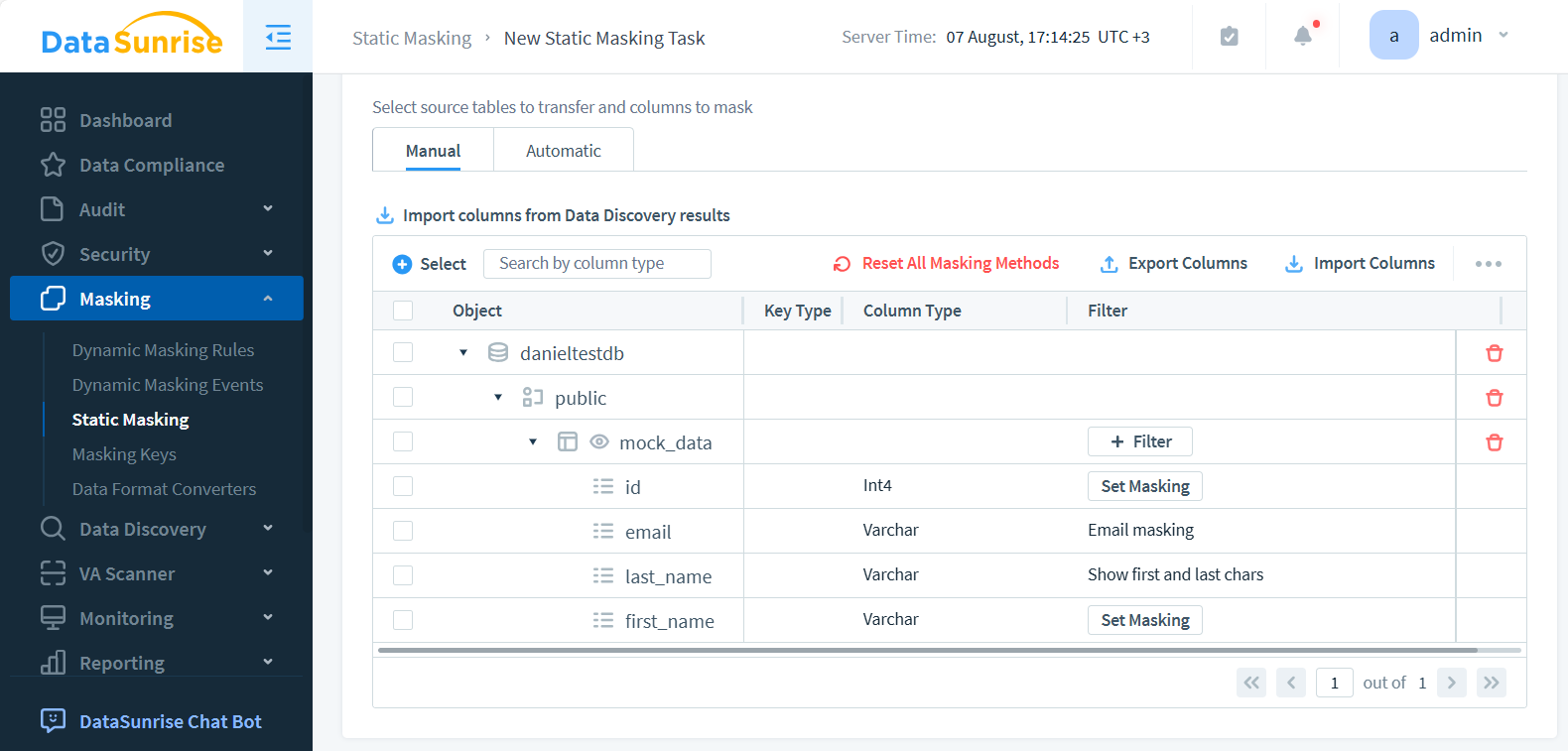
- Select your target database objects to mask
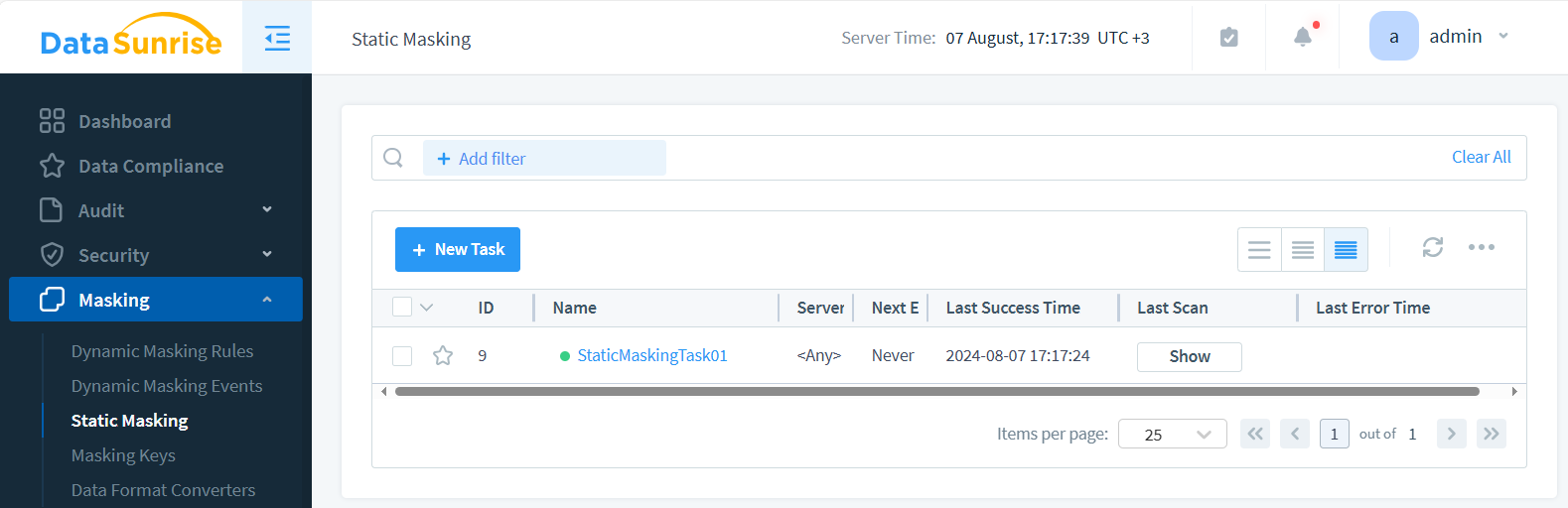
- Save and start the Task
The result in the target table may look as follows (queried in DBeaver):
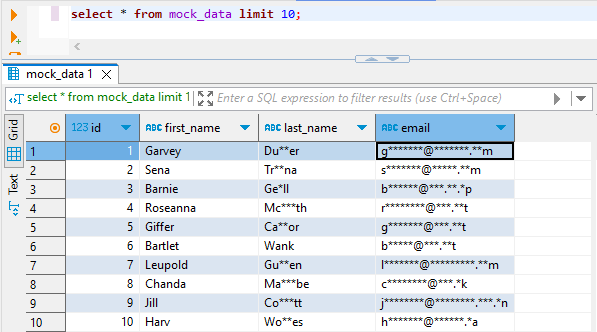
DataSunrise Masking Methods
DataSunrise provides a comprehensive suite of data masking techniques. Let’s explore some of the most powerful and commonly used methods:
- Format Preserved Encryption keeps the original data format intact while encrypting it, ensuring the data remains usable after encryption. This means that the encrypted values will still look similar to the original data, making it easier to work with and analyze. This is especially useful in situations where the format of the data is important for processing or displaying purposes.
- Fixed String Value is a technique used to replace sensitive data with a predefined string. This can be useful for masking sensitive information such as credit card numbers or social security numbers. Replacing the actual data with a fixed string protects the sensitive information from unauthorized access or viewing.
- Null Value is another method of protecting sensitive data by replacing it with a NULL value. This removes sensitive information from the dataset, so no one can access or retrieve the original data. This method may not keep the data format like Format Preserved Encryption, but it effectively keeps sensitive information secure.
DataSunrise offers a wide array of masking methods, giving you flexible options to protect your data without sacrificing usability. With over 20 distinct techniques available, you can fine-tune your data protection strategy to meet specific needs.
Benefits of Static Data Masking for Amazon Redshift
Implementing static data masking in Redshift offers several advantages:
- Enhanced data security
- Simplified regulatory compliance
- Reduced risk of accidental data exposure
- Improved development and testing processes
- Maintained data utility
By masking sensitive data, you can confidently share information across your organization without compromising security.
Challenges and Considerations
While static data masking is beneficial, there are some challenges to consider:
- Performance impact during masking process
- Maintaining referential integrity in masked data
- Ensuring consistent masking across related tables
- Balancing data usability with security requirements
Addressing these challenges requires careful planning and implementation.
Conclusion
Static data masking for Amazon Redshift is a powerful tool for protecting sensitive data. Organizations can use built-in and custom functions. These functions help create secure and hidden copies of their data. This is useful for testing and development purposes.
Remember, data protection is an ongoing process. Regularly review and update your masking strategies to stay ahead of evolving threats and compliance requirements.
For those seeking more advanced, real-time protection, solutions like DataSunrise offer data masking capabilities. DataSunrise provides user-friendly and cutting-edge tools for database security, including audit and data discovery features. To learn more about how DataSunrise can enhance your data protection strategy, visit our website for an online demo.
