
Static Data Masking in Greenplum: Enhancing Data Security and Compliance

Greenplum, a powerful open-source data warehouse, offers robust features for managing and analyzing large datasets. As organizations deal with increasing amounts of sensitive information, the need for effective data protection methods has become paramount. Static data masking protects sensitive information in Greenplum while still allowing users to utilize it for different needs. This article explores the concept of static data masking in Greenplum, its benefits, challenges, and best practices for implementation.
Static Data Masking: Definition and Benefits
Static data masking is a process that replaces sensitive data with realistic but fictitious information. This method helps organizations keep their important data safe. It also lets them use the masked data for testing, development, or analyzing.
In Greenplum, static data masking adds extra security. It keeps sensitive information private, even when shared with unauthorized users or moved to non-production environments.
The main goal of static data masking is to make a version of the data. This new version looks and acts like the original. However, it does not have any sensitive information.
This method lets organizations use hidden data for different reasons. It keeps the original data safe and private.
Implementing static data masking in Greenplum offers several significant advantages:
Enhanced Data Security: By replacing sensitive information with fictitious data, organizations can significantly reduce the risk of data breaches. Even if unauthorized users access the masked data, they cannot extract any valuable or sensitive information.
Regulatory Compliance: Many industries are subject to strict data protection regulations such as GDPR, HIPAA, or PCI DSS. Static data masking helps organizations follow these rules. It ensures that sensitive data does not appear in non-production environments.
Improved Testing and Development: Static data masking allows organizations to use production-like data in testing and development environments. This approach gives more accurate and reliable test results. Developers and testers can use data that looks like real-world situations. They can do this without risking sensitive information.
Cost Reduction: Using masked data instead of synthetic datasets helps organizations. This is especially useful when preparing data for non-production purposes. This efficiency can lead to significant cost savings in the long run.
Data Sharing: Static data masking enables organizations to share data with third-party vendors, partners, or offshore development teams without exposing sensitive information. This capability facilitates collaboration while maintaining data security.
Challenges and Techniques
While static data masking offers numerous benefits, it also presents some challenges that organizations need to address:
Maintaining Data Consistency: One of the biggest challenges is ensuring that masked data remains consistent across related tables. To maintain the referential integrity of the database, we must preserve relationships between different data elements.
Preserving Data Utility: The masked data should keep the same patterns and features as the original data. This is important for analyzing and testing. Striking the right balance between data protection and data utility can be challenging.
Performance Impact: The masking process can take a lot of time and resources. This depends on the techniques used and the amount of data. Organizations need to consider the performance impact on their Greenplum environment.
Identifying Sensitive Data: Thoroughly identifying all sensitive data elements within a complex database structure can be a daunting task. Missing even a single sensitive field can compromise the entire masking effort.
Greenplum provides various methods for implementing static data masking. These include built-in functions, third-party tools, and custom scripts. Some common techniques used in Greenplum static data masking include:
Substitution: This technique involves replacing sensitive data with realistic but fake values.
Shuffling: This method involves randomizing values within a column. Maintaining the overall statistical properties of the data while obscuring individual records is particularly useful.
Encryption: You can transform sensitive data using encryption algorithms. While this method provides strong protection, it may limit the usability of the data for certain purposes.
Best Practices and Implementation
To maximize the effectiveness of static data masking in Greenplum, consider the following best practices:
Identify Sensitive Data: Thoroughly analyze your Greenplum database to identify all sensitive data elements. This step makes sure that the masking process does not overlook any confidential information.
Choose Appropriate Masking Techniques: Select masking techniques that best suit your data types and security requirements. Different data elements may require different masking approaches to maintain data integrity and usability.
Maintain Data Relationships: When you mask data across multiple tables, ensure that you preserve the relationships between the tables. This step is crucial for maintaining data consistency and avoiding issues in applications that rely on these relationships.
Document Masking Rules: Maintain clear documentation of all masking rules and procedures. This documentation should include the masked fields, the techniques used, and any exceptions or special cases.
Creating a Separate Table with Masked Data
Here’s an example of how to create a separate table filled with masked data in Greenplum:
-- Original table
CREATE TABLE customer_data (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
credit_card VARCHAR(16),
date_of_birth DATE
);
-- Insert sample data
INSERT INTO customer_data (name, email, credit_card, date_of_birth)
VALUES ('John Doe', 'john@example.com', '1234567890123456', '1980-05-15');
-- Create masked table
CREATE TABLE masked_customer_data AS
SELECT
id,
'Customer_' || id AS masked_name,
'user_' || id || '@masked.com' AS masked_email,
SUBSTRING(credit_card, 1, 4) || 'XXXXXXXXXXXX' AS masked_credit_card,
date_of_birth + (RANDOM() * 365 * INTERVAL '1 day') AS masked_date_of_birth
FROM customer_data;
-- View masked data
SELECT * FROM masked_customer_data;
This example creates a new table called `masked_customer_data` with masked versions of sensitive fields. We change the `name` to “Customer_” followed by the ID.
The system hides the `email` in a masked format. The `credit_card` shows only the first four digits. They replace the rest with ‘X’ characters.
A random number of days moves the `date_of_birth`. This can be up to a year. This keeps the general age distribution while hiding exact birth dates.
Implementation via DataSunrise
Greenplum helps users mask static data. However, this can be complicated and slow for large databases. In such circumstances, we suggest using third-party solutions. To start this in DataSunrise, you must create an instance of a Greenplum database.
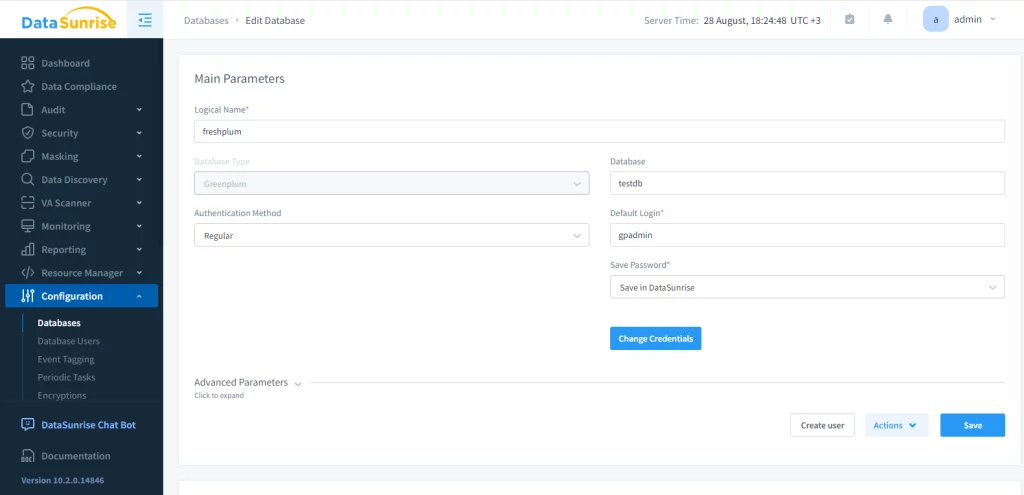
The instance allows to interact with the source database through audit, masking and security rules and tasks. Next, we need to configure a static masking task. This step has three actions: choose the starting server, select the source and target databases (both must be Greenplum), and set masking rules. For integrity reasons, we encourage truncating the target schema.
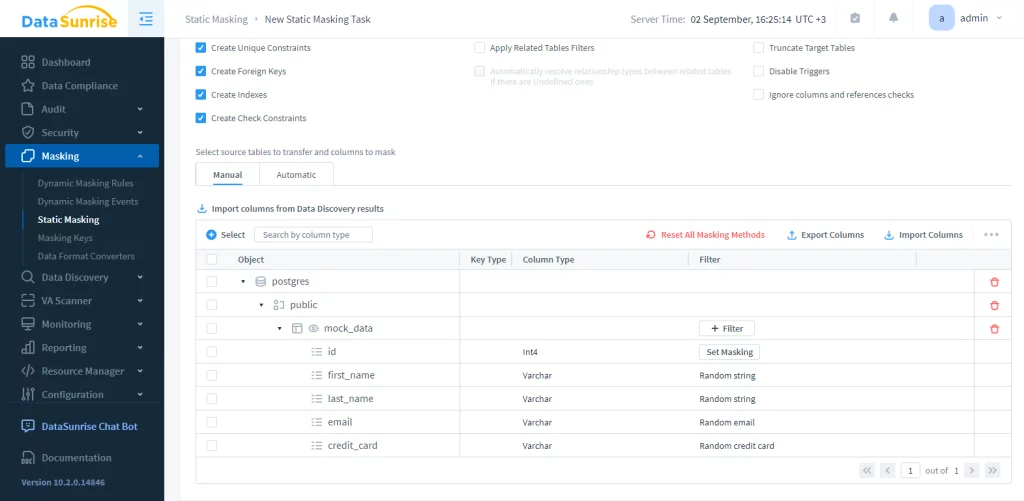
In this example the masked table is mock_data in postgres database. You just need to start the task. The result is as follows:

Conclusion
Static data masking in Greenplum is a powerful technique for enhancing data security and compliance. Organizations can safeguard sensitive information by using effective methods while still keeping data usable for testing, development, and analyzing.
Data privacy concerns are increasing, and rules are tightening. Static data masking is crucial for businesses using Greenplum to keep their data safe. Organizations can use the insights from this article to create effective static data masking strategies. This will help protect sensitive information while still allowing them to use their valuable data effectively.
