
Static Data Masking in PostgreSQL: Techniques, Benefits, and Best Practices

Data protection is crucial for businesses handling sensitive information. PostgreSQL, a powerful open-source database system, offers various security features. One such feature is static data masking. This article explores static data masking in PostgreSQL, its benefits, and how to implement it effectively.
What is Static Data Masking?
Static data masking is a technique that replaces sensitive data with realistic but fake information. This process happens before data moves to non-production environments. It helps protect confidential information while allowing developers and testers to work with accurate data representations.
PostgreSQL static data masking involves several steps. First, you identify sensitive data.
Then, you choose appropriate masking techniques. Next, you create masked copies of the original data. Finally, you replace original data with masked data in non-production environments.
Common Static Data Masking Techniques
PostgreSQL offers various masking techniques. Substitution replaces sensitive data with fake but realistic values. For example, replacing real names with randomly generated ones.
Shuffling rearranges data within a column. It maintains data distribution but breaks the link between records. Numeric alteration modifies numeric values while preserving their statistical properties. Date shifting moves dates forward or backward by a fixed period.
Implementing Static Data Masking in PostgreSQL
To implement static data masking in PostgreSQL, start by identifying sensitive data. Review your database schema and identify columns containing sensitive information.
Next, create masking rules. Develop rules for each sensitive data type. Ensure the masked data remains useful for testing and development.
Write masking queries to apply your rules. Here’s an example that creates a new table with masked data:
-- Create a new table for masked data
CREATE TABLE masked_customers AS
SELECT
id,
MD5(RANDOM()::TEXT) AS masked_name,
CONCAT(
SUBSTRING(MD5(RANDOM()::TEXT) FOR 8),
'@example.com'
) AS masked_email,
CASE
WHEN age < 18 THEN 'minor'
WHEN age BETWEEN 18 AND 65 THEN 'adult'
ELSE 'senior'
END AS masked_age_group,
ROUND(credit_score / 100) * 100 AS masked_credit_score
FROM customers;
-- Add any necessary indexes
CREATE INDEX ON masked_customers (id);
This example creates a new table called `masked_customers` based on the original `customers` table. It applies different masking techniques:
- Names are replaced with random MD5 hashes.
- The system masks emails with random strings and a generic domain.
- People categorize ages into groups.
- Credit scores are rounded to the nearest hundred.
Test your masking queries on a small dataset to ensure they work correctly. Then, create a masked copy of your production database and apply the masking queries to this copy. Verify that the masked data properly conceals sensitive information. Finally, use this masked table for non-production environments.
Implementation via DataSunrise
Using only native tools, it's possible to do static masking. However, it could be challenging with a substantial database. To simplify the process, we suggest using third-party solutions like DataSunrise. The order of implementation is next:
Firstly, an instance of PostgreSQL database must be created.
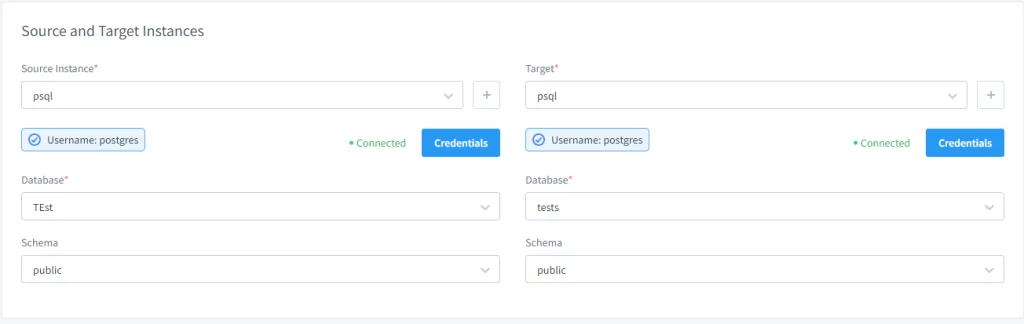
Then, configure the static masking task. To do this, you must select the source and target databases and schemas. For integrity reasons, we recommend truncating the target schema before transferring data, although it is optional.
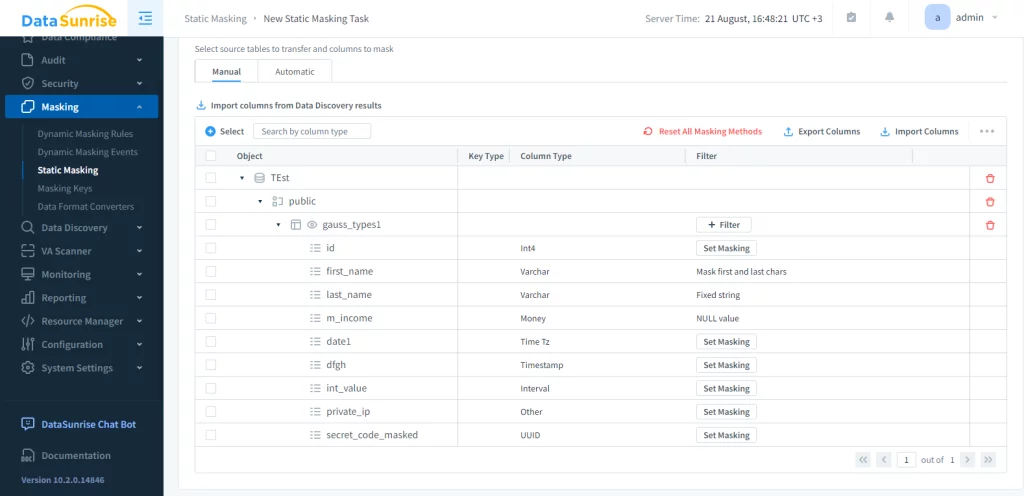
The next part of configuring the task is selecting masking methods.
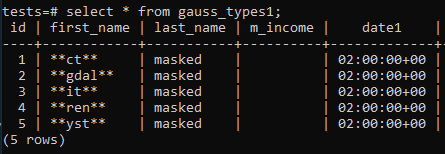
Just start the task. You can schedule or start this process manually at any moment. The result is as follows:
Best Practices and Challenges
Follow best practices to maximize the effectiveness of your static data masking. Ensure consistency across tables and preserve referential integrity. Update your masked data periodically and document your masking rules. Use strong access controls to limit access to both original and masked data.
Static data masking comes with challenges. Masking large datasets can be time-consuming and resource-intensive. Balancing data protection with maintaining useful data for testing can be tricky. Masking data in databases with complex relationships requires careful planning.
Conclusion
Several tools can help with PostgreSQL static data masking. pgMemento is an open-source PostgreSQL extension for auditing and data masking. Dataedo is a database documentation and data masking tool supporting PostgreSQL. PostgreSQL Anonymizer is an extension that provides dynamic data masking capabilities.
Static data masking in PostgreSQL is a powerful technique for protecting sensitive information. Organizations can protect data privacy, follow rules, and keep data accurate for non-production purposes by doing it right. As data protection becomes increasingly important, mastering PostgreSQL static data masking is a valuable skill for database administrators and developers alike.
