
Potential of Synthetic Data Generation
In today’s data-driven world, there’s an increasing demand for diverse datasets for various purposes like testing, training, and development. However, obtaining real-world data comes with challenges such as privacy concerns, data availability issues, and regulatory restrictions. Synthetic data generation offers a solution to these challenges by creating artificial data that mimics real data characteristics without compromising privacy or security. In this article, we’ll take a closer look at synthetic data and the Synthetic Data Generator feature provided by DataSunrise.
Understanding Synthetic Data
Data Synthetic data is artificially generated data that resembles real-world data in terms of statistical properties, patterns, and structures. But it doesn’t contain any actual information about individuals or entities. It’s created using algorithms and mathematical models to maintain authenticity while avoiding the risks associated with handling sensitive data.
In simpler terms, synthetic data is like a virtual replica of real information. Instead of using actual sensitive data, synthetic data provides a safe alternative for testing, training AI models, or running simulations without exposing any real personal details.
Applications of Synthetic Data
Synthetic data finds its myriad applications across diverse domains and purposes. Companies, eschewing real data fraught with the specter of data breaches, increasingly turn to synthetic data to expedite the creation of fictitious datasets. Here are some pivotal applications:
- Data Privacy and Security Testing
- Machine Learning Model Training
- Software Development and Testing
- Healthcare Analytics
Synthetic data is used to assess the security systems of organizations, especially in sectors like finance, healthcare, and legal, without exposing real sensitive information.
More and more industries use synthetic data to train machine learning models without compromising the privacy of actual data.
Synthetic data is helpful in software development by providing realistic datasets for creating and evaluating applications, especially in industries like telecommunications.
Synthetic data enables researchers and data scientists to conduct studies and experiments in healthcare without breaching patient confidentiality.
DataSunrise Synthetic Data Generation
DataSunrise offers a Synthetic Data Generation feature that accurately mimics real-life data. It can be used for various business purposes, from developing and testing to improving machine learning algorithms.
For example, if there’s a need to generate random data from sales team that includes emails, dates, times, credit card numbers, and IDs for statistical analysis, synthetic data can be used instead of real one to protect privacy, especially in industries dealing with sensitive information like healthcare or finance.
You need to generate new data instead of the ones you have. Let’s create a synthetic data set with DataSunrise.
Go to the Configuration – Periodic Tasks. Click +New task.
Picture 1. Periodic Tasks
In the General Settings subsection set the name for your Periodic Task, select the type of the task – Synthetic Data Generation -, and on which server to start. In the Synthetic Data Generation subsection select the database instance.
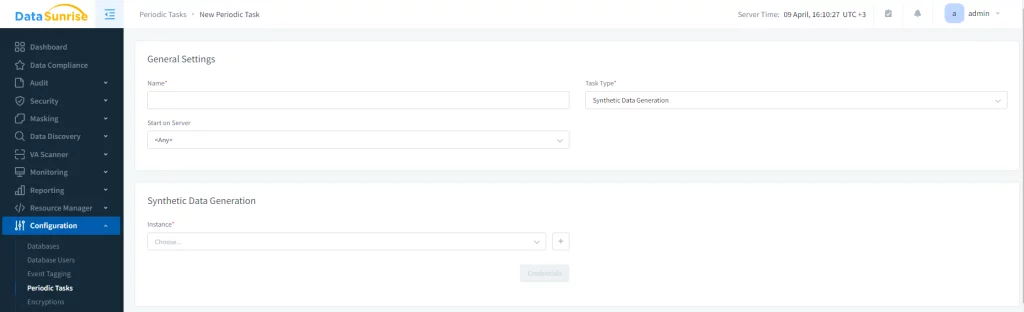
Picture 2. General settings
Further, in the Generated Tables subsection select the needed check boxes (we enabled only the check box for Empty Target Table and Skip Table Generation on Error).
Here, click +Select. There will be a window to select the database objects you need. Select a database, schema, table, and column for which synthetic data will be generated. After everything is selected, click Save.
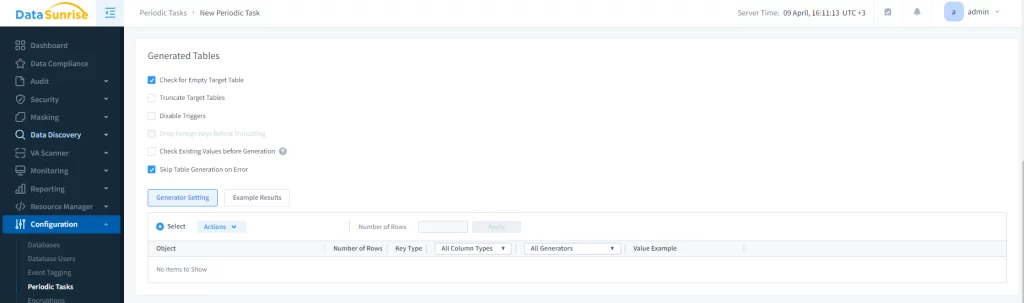
Picture 3. Selecting Database Objects
After that, you will see the provided generators and Value Examples for each object. In the All Generators column, you can select or create the needed generator.
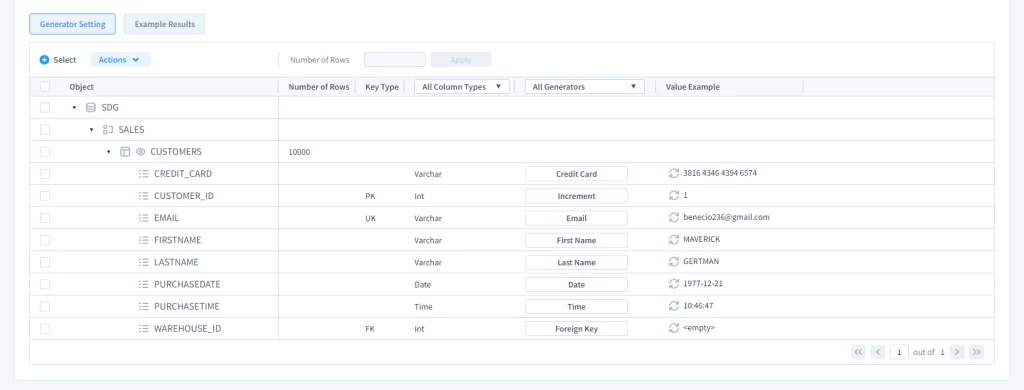
Picture 4. Selecting Data Generators
In the Example Results section, we see the list of generated data. After everything is done, click Apply or Save.
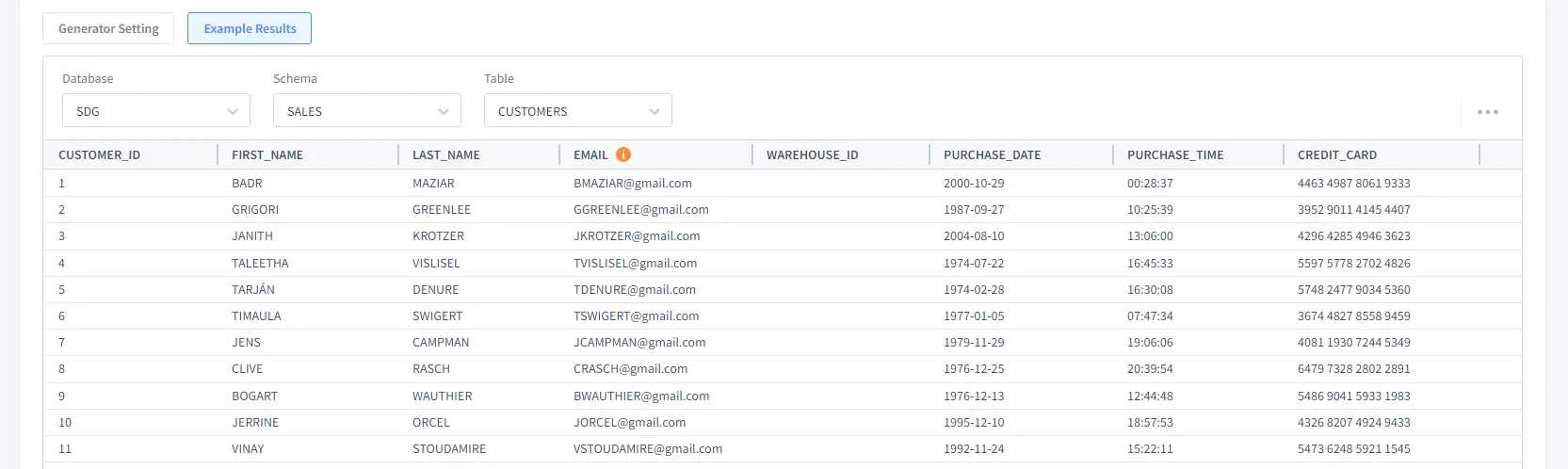
Picture 5. Generated Data Set Example
Also, if you want to create your own specific generator, go to the Configuration – Generators, and click +Create Generator. There you can select a generator type and specify its parameters. Click Save and you will be able to apply your generator in the Synthetic Data Generation Task.
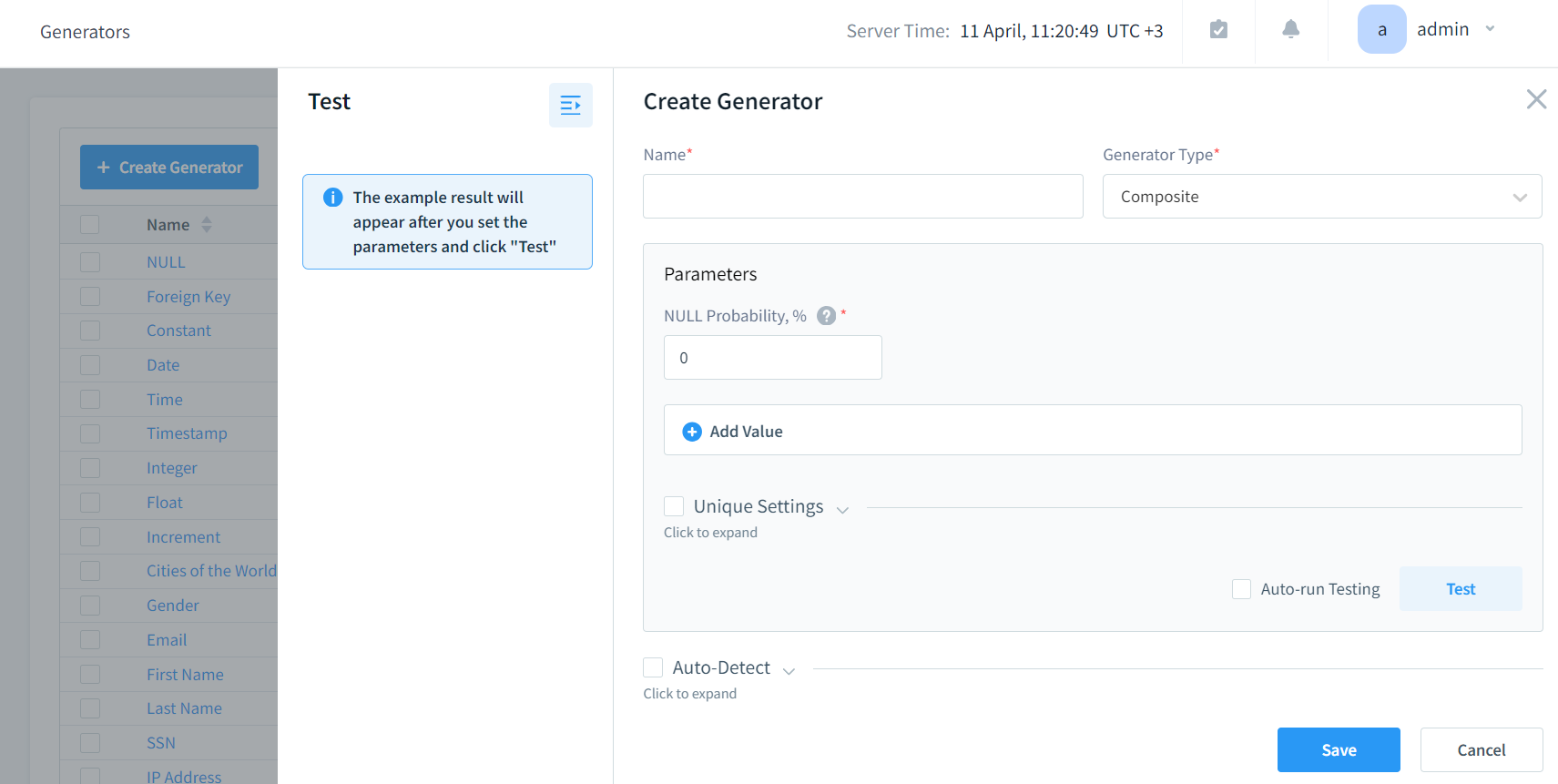
Picture 6. Generator Creation
The generation of synthetic data is simple and easy.
Conclusion
DataSunrise simplifies this process, making it easy to integrate synthetic data into various workflows.
Moreover, it’s essential to note that while synthetic data offers many advantages, it’s crucial to validate its effectiveness and reliability. Organizations should ensure that the synthetic data accurately represents the real data distribution and maintains the necessary relationships and dependencies.
Synthetic Data Generation provides a valuable solution for organizations looking to work with realistic data while safeguarding privacy and security concerns. With the DataSunrise Synthetic Data Generation feature, organizations can confidently navigate the data landscape and harness the power of synthetic data for their business needs.
